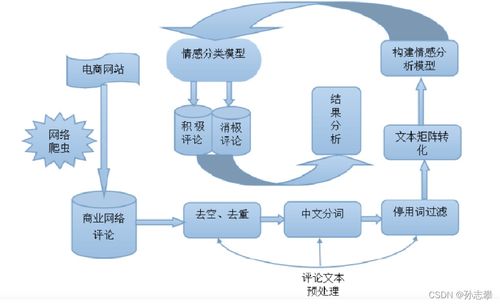
随着电子商务的蓬勃发展,海量产品评论数据成为企业洞察消费者情感和优化产品策略的重要资源。基于Python的文本挖掘技术,结合高效的数据处理与存储服务,能够系统地对电商评论进行情感分析,为业务决策提供支持。本报告将详细阐述数据处理和存储服务的核心环节,包括数据采集、清洗、特征提取、情感分析建模以及数据存储方案。
一、数据采集与预处理
电商平台的产品评论数据通常来源于API接口或网页爬虫工具(如Scrapy、BeautifulSoup)。在数据采集阶段,需确保遵守平台规则,避免过度请求。采集到的原始数据常包含噪声,如HTML标签、特殊字符、重复评论等,因此预处理是情感分析的基础。预处理步骤包括:
- 数据清洗:移除无关字符、停用词(使用NLTK或jieba库)和标点符号。
- 文本规范化:统一大小写、处理缩写词和拼写错误,例如通过正则表达式或spaCy库。
- 分词处理:对中文评论使用jieba分词,英文评论使用NLTK的word_tokenize,将文本转换为词语序列。
二、特征提取与情感分析建模
在数据预处理后,需将文本转换为数值特征,以用于机器学习模型。常用的特征提取方法包括:
- 词袋模型(Bag of Words) 和 TF-IDF:通过sklearn库的CountVectorizer和TfidfVectorizer实现,捕捉词语频率信息。
- 词嵌入(Word Embeddings):如Word2Vec或GloVe,使用gensim库生成词语的分布式表示,适合深度学习模型。
情感分析建模通常采用监督学习或深度学习的方法:
- 监督学习模型:如朴素贝叶斯、支持向量机(SVM)或随机森林,使用已标注的情感标签(正面、负面、中性)进行训练。模型评估可通过准确率、召回率和F1-score等指标。
- 深度学习模型:如LSTM或BERT,利用TensorFlow或PyTorch框架构建,能够处理长文本和复杂情感表达。预训练模型(如BERT)在电商评论中表现优异,但需大量计算资源。
三、数据处理与存储服务
为确保分析流程的可扩展性和效率,数据处理和存储服务需设计为模块化系统:
- 数据处理流水线:使用Apache Spark或Dask进行分布式处理,处理大规模评论数据。流水线包括数据清洗、特征提取和模型推理,可通过Airflow或Luigi实现自动化调度。
- 数据存储方案:根据数据量和使用场景选择存储方式:
- 关系型数据库:如MySQL或PostgreSQL,适用于结构化数据和查询频繁的场景,存储情感分析结果和元数据。
- NoSQL数据库:如MongoDB,适合存储半结构化的评论原文和情感标签,便于扩展。
- 云存储服务:如AWS S3或Google Cloud Storage,用于备份原始数据和中间结果,支持高可用性。
- API服务与可视化:构建RESTful API(使用Flask或FastAPI)提供情感分析服务,并通过可视化工具(如Tableau或Matplotlib)展示情感分布和趋势报告。
四、优势与挑战
基于Python的文本挖掘结合数据处理存储服务,优势包括:开源库丰富、成本低廉、易于集成;但挑战在于数据隐私合规、模型泛化能力以及实时处理需求。未来,可探索结合实时流处理(如Kafka)和边缘计算,以提升电商场景的响应速度。
通过系统化的数据处理和存储服务,电商产品评论情感分析能够有效挖掘用户反馈,助力企业优化产品和营销策略,实现数据驱动的商业价值。









