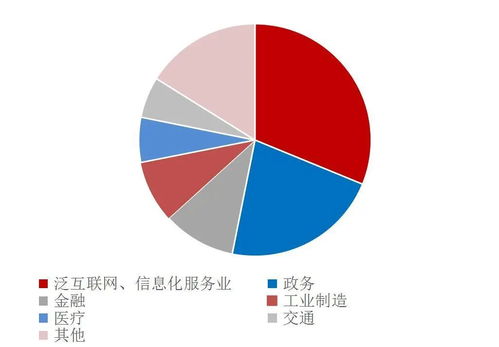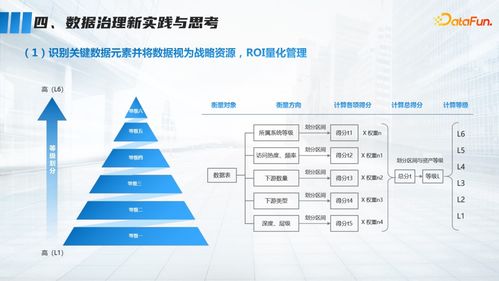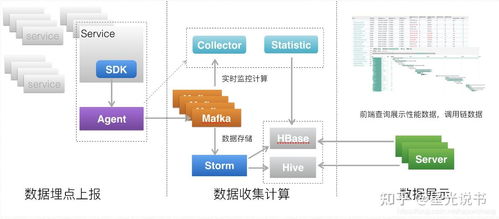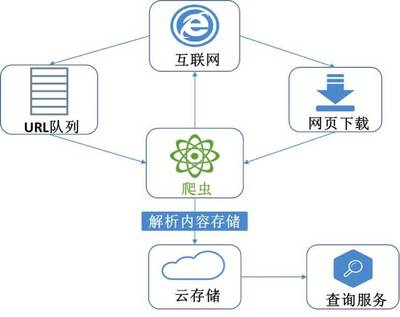
与亚马逊首席技术官Werner Vogels深入探讨分布式系统设计,是一次难得的经验。他强调,在当今数据驱动的时代,构建可靠、可扩展的分布式系统是企业成功的基石。以下是基于对话整理的关键见解:
分布式系统设计的核心原则
- 容错性优先:系统必须在组件失败时仍能正常运行。采用冗余设计、故障隔离和自动恢复机制,确保单点故障不影响整体服务。
- 可扩展性:通过水平扩展(如添加更多节点)而非垂直扩展(升级硬件)来应对负载增长。亚马逊的微服务架构和负载均衡技术是典型例子。
- 松耦合设计:模块化组件通过API交互,减少依赖。这允许团队独立部署和更新服务,提升开发效率。
- 最终一致性:在分布式环境中,强一致性可能牺牲性能。采用最终一致性模型(如Amazon DynamoDB),在保证数据正确性的同时优化响应时间。
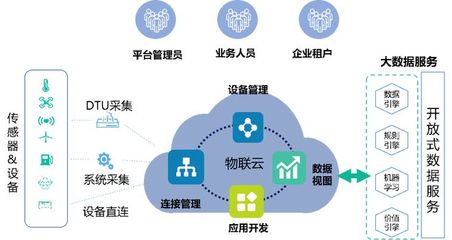
数据处理服务的策略
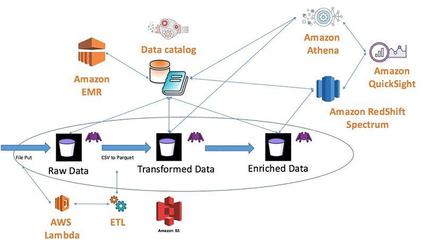
数据处理是分布式系统的核心。Werner指出,亚马逊采用事件驱动架构和流处理技术(如Amazon Kinesis)来处理实时数据。关键点包括:
- 数据分区:将数据分布到多个节点,避免热点问题。例如,Amazon S3使用对象存储和分片策略。
- 异步处理:通过消息队列(如Amazon SQS)解耦生产者和消费者,提高系统吞吐量。
- 批处理与流处理结合:使用Amazon EMR进行大数据批处理,同时用Kinesis处理实时流,满足多样化需求。
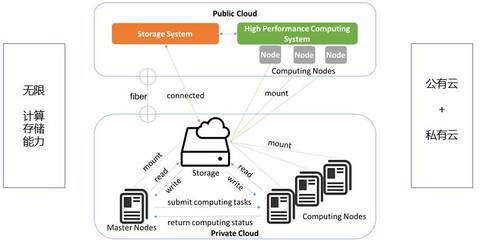
存储服务的设计考量
存储服务需平衡性能、成本和可靠性。Werner分享了亚马逊的经验:
- 多模型存储:根据数据特性选择合适存储,如关系数据库(Amazon RDS)、NoSQL(DynamoDB)或对象存储(S3)。
- 数据复制与备份:跨区域复制数据(如Amazon S3的跨区域复制)以防灾难,并定期备份到低成本存储(如Amazon Glacier)。
- 安全性:加密数据在传输和静态状态,使用IAM策略控制访问权限。
实践建议
Werner总结道,设计分布式系统时,应从小规模开始,逐步迭代。监控和日志(如Amazon CloudWatch)至关重要,用于快速诊断问题。拥抱开源工具(如Kubernetes)可加速开发,但需定制以适应业务需求。
分布式系统的设计是一场权衡游戏,需在一致性、可用性和分区容错性之间找到平衡。借鉴亚马逊的实践,企业可构建 resilient 的数据处理与存储服务,驱动创新与增长。